从 R1 到 Sonnet 3.7,推理模型首轮竞赛中有哪些关键信号?
文章摘要
【关 键 词】 推理模型、竞争分析、技术趋势、人工智能、开发者
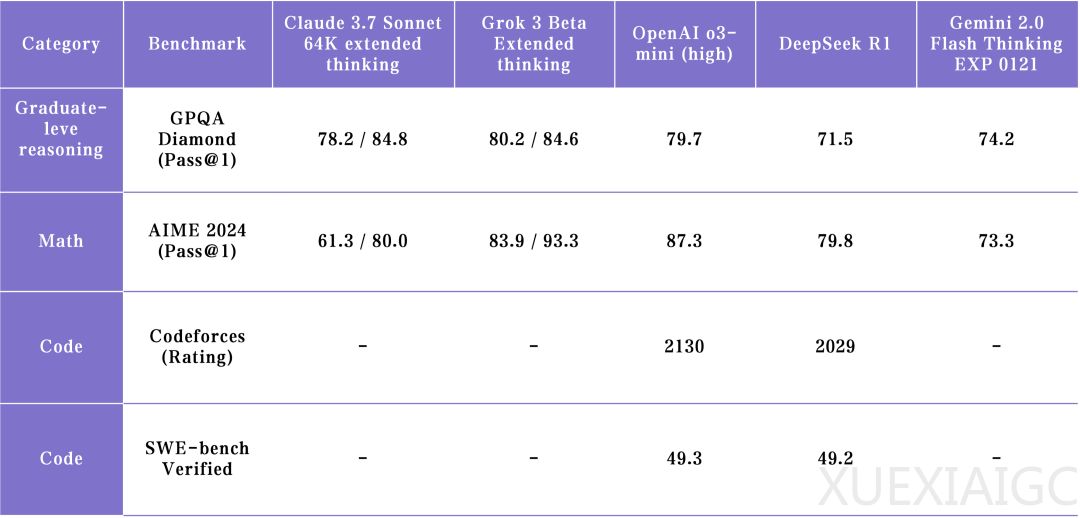
过去一个月,头部AI实验室密集发布了多个推理模型,标志着推理模型领域的第一轮竞争暂时告一段落。OpenAI、xAI和Anthropic分别推出了各自的顶尖模型:o3-mini、Grok 3和Claude 3.7 Sonnet。尽管这些模型在某些领域表现突出,但尚未出现全面领先的SOTA模型。OpenAI的o3-mini在数学解题能力上表现优异,而xAI的Grok 3在推理速度上更具优势,Anthropic的Claude 3.7 Sonnet则在解决真实世界工程问题上表现最佳。整体来看,推理模型的发展仍处于强化学习(RL)扩展的早期阶段,未来可能会有更大的技术突破。
在模型的具体表现上,o3-mini在数学和推理任务中表现突出,但其在多样化创作内容上的能力不如Grok 3和DeepSeek模型。Grok 3在短时间内追赶上了o3-mini的水平,尤其是在推理速度上表现优异,但其开发资源投入巨大,尚未揭示新范式的启发意义。Claude 3.7 Sonnet在工程代码和实际问题的解决上表现最佳,尤其是在AI Coding Agent产品应用中具有显著优势。Gemini 2.0 Flash则在多模态理解能力上领先,但其推理能力的表现相对均衡,缺乏明显的长板。DeepSeek R1在有限资源下进行了大量创新,尽管当前表现落后,但未来有望通过持续进步缩小差距。
在最强LLM基础模型的竞争中,Grok 3的基础模型能力可能已经超越了GPT 4.5,尤其是在任务表现和风格上更具优势。然而,如何通过强化学习和后训练进一步激发基础模型的能力,仍然是未来发展的关键。此外,基础模型的预训练依然至关重要,高质量的预训练模型是强化学习推理模型的基础,尽管当前的市场质疑预训练的边际收益是否已经枯竭,但基础模型的探索仍将继续。
Claude 3.7 Sonnet的混合推理模型(Hybrid Reasoning Model)被认为是未来模型发布的新范式。该模型结合了LLM和推理模型的优势,用户可以根据需求选择快速思考或慢速思考模式,这种设计有望成为后续模型发布的标准配置。此外,Claude 3.7 Sonnet在AI Coding领域的表现尤为突出,其可靠代码输出长度显著提升,推动了AI Coding产品的应用场景扩展。
在AI Coding领域,Claude Code的发布标志着Anthropic进一步强化了其在AI Coding产品中的基建作用。Claude Code通过命令行界面展示了强大的工具使用能力,能够深入理解代码库并进行自我修正,推动了AI Coding向更深入的开发工作流迈进。此外,Claude 3.7 Sonnet在解决真实世界问题上的表现尤为突出,尤其是在debug、代码库搜索和代理工作流规划等任务中表现最佳。
在AI Agent的落地方面,Claude 3.7的action scaling能力、可验证环境和持续学习能力为AI Agent的未来发展提供了关键的技术路线图。RL带来的action scaling能力确保了工具使用的可靠性和长程推理的准确性,而可验证环境和持续学习能力则为AI Agent在开放性问题中的泛化能力提供了支持。
OpenAI的Deep Research被认为是RL扩展范式下第一个具备产品市场契合度(PMF)的产品形态。Deep Research在深度研究任务中的表现优于其他类似产品,尤其是在网页内容理解、信息幻觉控制和用户意图识别等方面表现出色。此外,RL Fine-tuning在垂直领域的落地效果虽然不如RL Scaling,但在特定场景下仍能保证推理模型的落地效果。
总的来说,推理模型领域的竞争仍然激烈,尽管尚未出现全面领先的模型,但各家的技术探索和创新为未来的发展奠定了坚实的基础。随着RL扩展的深入和基础模型的持续优化,推理模型领域有望迎来更大的技术突破。
原文和模型
【原文链接】 阅读原文 [ 4761字 | 20分钟 ]
【原文作者】 Founder Park
【摘要模型】 deepseek/deepseek-v3/community
【摘要评分】 ★★★★★


相关文章



