从零开始,用英伟达T4、A10训练小型文生视频模型,几小时搞定
文章摘要
【关 键 词】 文本生成、视频模型、深度学习、生成对抗网络、AI应用
文本生成视频模型是2024年AI领域的热门趋势之一,继大语言模型之后备受关注。本文作者Fareed Khan介绍了如何构建一个小型的文本生成视频模型,从理解理论概念到实现架构,再到生成最终结果的全过程。
由于资源限制,作者选择了小规模架构,并比较了不同处理器上训练模型所需的时间,指出CPU训练耗时长,推荐使用Colab或Kaggle的T4 GPU以提高效率。
构建目标遵循传统机器学习或深度学习模型的方法,在数据集上训练并在未见过的数据上测试。以文本转视频为例,假设有一个包含10万个狗捡球和猫追老鼠视频的训练数据集,训练模型生成猫捡球或狗追老鼠的视频。
尽管这类数据集容易获得,但算力需求极高,因此本文使用Python代码生成的移动对象视频数据集,并采用生成对抗网络(GAN)架构而非OpenAI Sora使用的扩散模型。
准备工作包括对面向对象编程(OOP)、神经网络和GAN架构的基本了解。GAN是一种深度学习模型,包含两个相互竞争的神经网络:生成器创建新数据,判别器评估数据真实性。
GAN在真实世界有多种应用,如生成图像、数据增强、补充缺失信息和生成3D模型。GAN由生成器和判别器组成,在对抗训练中不断提高性能,直至生成的数据与原始数据无法区分。
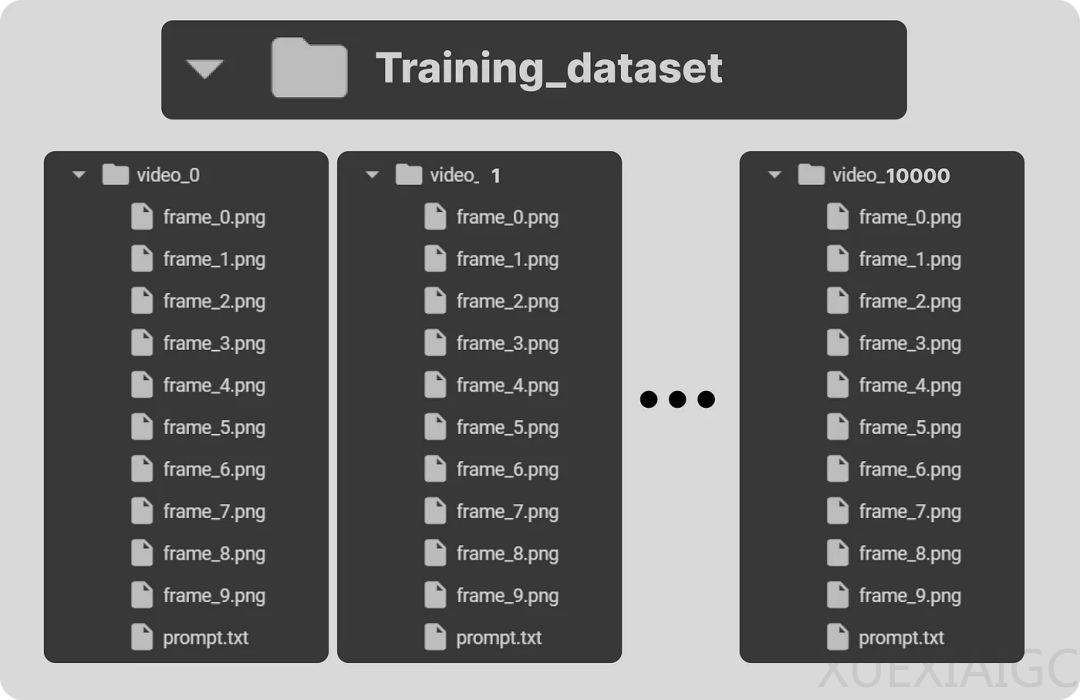
本文使用一系列Python库,包括操作系统、随机数生成、数值运算、图像处理、深度学习等。定义训练数据时,需要至少10000个视频,因为较小数量的视频效果不佳。
训练视频数据集包括不同方向和运动方式移动的圆圈视频。根据文本提示生成训练视频,定义了圆的多个运动轨迹,并编写数学公式根据提示移动圆。
通过上述步骤,本文展示了如何构建一个小型的文本生成视频模型,为读者提供了一个入门指南。尽管资源有限,但通过合理选择架构和利用现有工具,仍可实现有趣的AI应用。
原文和模型
【原文链接】 阅读原文 [ 5831字 | 24分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章




