模型信息
【模型公司】 月之暗面
【模型名称】 moonshot-v1-32k
【摘要评分】 ★★★★★
文章摘要
【关 键 词】 TimesFM、时间序列、Transformer、预训练、零样本
新智元报道了Google Research的研究人员提出了一个时序预测基础模型TimesFM,该模型针对时序数据设计,输出序列长于输入序列。TimesFM在1000亿时间点数据上进行预训练,仅用200M参数量就展现出超强的零样本学习能力。时间序列预测在多个领域具有重要应用,如零售、金融、制造业等。尽管深度学习模型在多变量时间序列预测任务中表现出色,但仍面临诸多挑战,如长时间训练和验证周期。
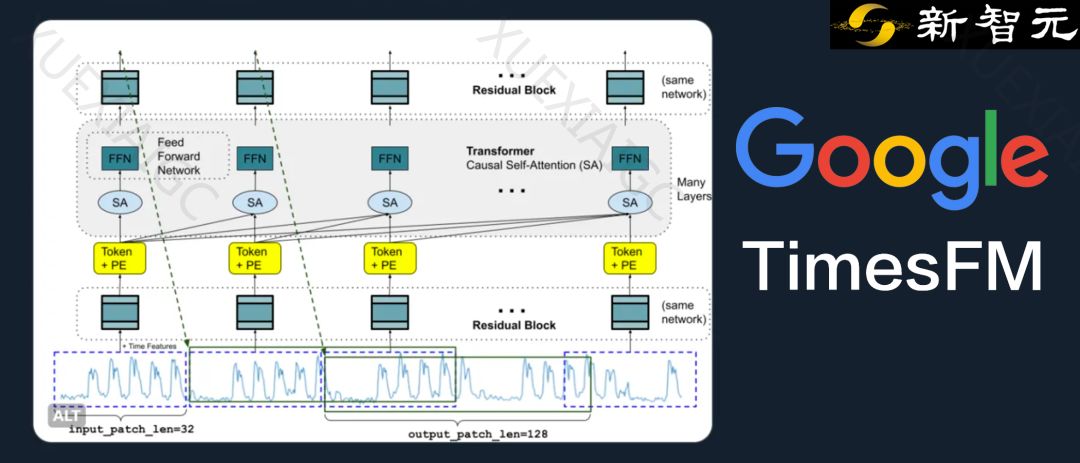
TimesFM模型采用堆叠的Transformer层作为主要构建块,与大型基础语言模型(LLMs)类似。但TimesFM在处理时间序列预测时存在关键区别,如需要具有残差连接的多层感知器块,以及输出patch长度可以大于输入patch长度。这使得TimesFM能够预测比输入patch长度更长的后续时间点。
研究人员发现合成数据和真实世界数据对于TimesFM的训练非常重要。合成数据有助于基础学习,而真实世界数据则增加了真实世界的感觉。在预训练过程中,研究人员使用了1000亿个真实世界时间点的大型语料库,其中包括Google趋势和维基百科的页面浏览量数据。
TimesFM在多个时间序列基准测试中表现出色,零样本性能优于许多统计方法(如ARIMA、ETS)以及强大的深度学习模型(如DeepAR、PatchTST)。在Monash Forecasting Archive数据集上,TimesFM的零样本性能优于大多数监督方法,甚至与经过明确训练的模型相当。此外,TimesFM在长期预测任务上也展现出良好的性能,与有监督PatchTST模型相匹配。
总之,TimesFM作为一个仅200M参数的预训练模型,在各种公共基准测试中展现出优异的零样本性能。研究人员计划今年晚些时候在Google Cloud Vertex AI中为外部客户提供TimesFM模型。
原文信息
【原文链接】 阅读原文
【阅读预估】 2266 / 10分钟
【原文作者】 新智元
【作者简介】 智能+中国主平台,致力于推动中国从互联网+迈向智能+新纪元。重点关注人工智能、机器人等前沿领域发展,关注人机融合、人工智能和机器人革命对人类社会与文明进化的影响,领航中国新智能时代。

相关文章





