为什么AI数不清Strawberry里有几个 r?Karpathy:我用表情包给你解释一下
文章摘要
【关 键 词】 AI问题、Token化、智能表现、模型改进、应用策略
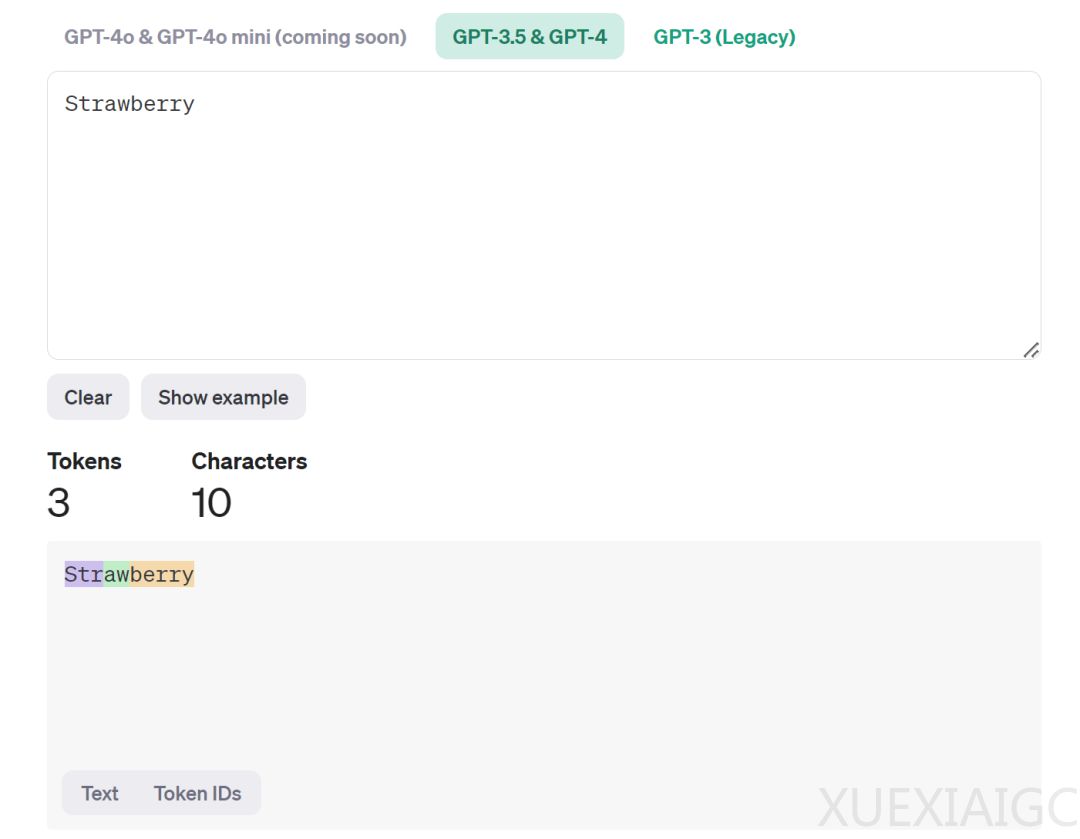
在AI领域,大型语言模型(LLM)的低级错误问题引起了广泛关注。Tokenization作为其中的关键因素,其将文本分解为token的过程可能导致模型对某些问题的理解出现偏差。例如,将”Strawberry”分解为Str-aw-berry,使得模型难以准确回答其中包含的字母数量。此外,”Schoolbooks”被分为school和books两个token,也反映了这一问题。
针对这一现象,AI教育行业的Karpathy开发了一个小程序,通过表情符号表示token,以直观展示大模型对文本的理解方式。然而,即使在明确要求模型分步骤解决问题的情况下,模型仍然可能因为过度自信而直接给出错误答案。这表明大模型可能存在两套系统:快速、直觉的系统1和慢速、计划性、逻辑性强的系统2,通常默认使用系统1。
Karpathy将这种现象称为”Jagged Intelligence”,即参差不齐的智能表现。与人类知识体系和解决问题能力的同步线性发展不同,大模型在某些领域表现出色,而在其他领域却表现不佳。这种现象的核心在于大模型缺乏”认知自我知识”,即对自身知识和能力的自我认知。如果模型具备这种能力,它将能够在面对不擅长的问题时主动寻求其他解决方案。
为了解决这一问题,可能需要在技术栈的各个方面进行改进,如在后训练阶段采用更复杂的方法。Karpathy推荐阅读Meta的Llama 3论文4.3.6章节,该章节提出了一些方法来让模型”只回答它知道的问题”。具体方法包括生成数据,使模型生成与预训练数据中的事实数据子集保持一致,并通过知识探测技术评估生成回答的正确性和信息量。此外,还应收集有限的标注事实性数据,以解决预训练数据与事实不一致或不正确的问题。
在实际应用中,应关注大模型的参差不齐的智能问题,尤其是在生产环境中。应致力于让模型只完成其擅长的任务,而不擅长的任务由人类及时接手。Meta的做法可以作为一种参考,同时也欢迎提出更好的解决方案。
原文和模型
【原文链接】 阅读原文 [ 1533字 | 7分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆


相关文章


