文章摘要
【关 键 词】 大模型、动态计算、参数效率、数据效率、模型架构
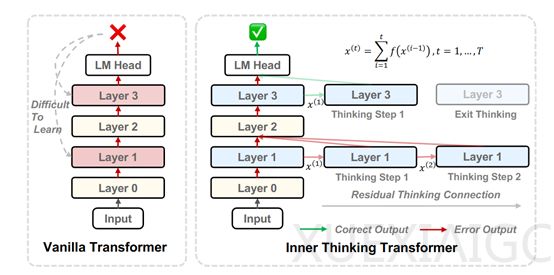
针对大模型参数规模扩大与性能提升不匹配的挑战,中国科学院信息工程研究所联合百度与北京师范大学AI学院提出了Inner Thinking Transformer架构(ITT)。该架构通过动态分配计算资源给单个标记,实现了无需增加模型参数即可提升推理能力的目标。其核心突破在于将传统Transformer的单次前馈过程重构为多步骤的隐式推理机制,为语言模型的计算资源优化开辟了新路径。
ITT架构包含三项核心技术:Residual Thinking Connection(RTC)机制通过迭代累积每个思考步骤的输出,使隐藏状态能逐步逼近最优解;Adaptive Token Routing(ATR)机制动态选择关键标记进行深度处理,相比传统方法减少约43%的计算开销;Thinking Step Encoding则为每个推理步骤赋予独特编码,解决了多步推理中的信息整合难题。这些创新使得模型在复杂任务中可自主扩展思考深度,同时避免参数量的线性增长。
在训练策略上,ITT采用多步优化替代单步梯度更新。通过将全局损失梯度与局部映射导数相结合,有效缓解了深度网络常见的梯度消失问题。实验数据显示,使用RedPajama数据集训练时,162M参数的ITT×4模型在50%网络层实施四步推理,性能较基线Transformer提升1.7%,远超同类循环架构0.3%的改进幅度。值得注意的是,ITT仅需基线模型56.8%的训练数据即可达到同等性能水平,这一突破显著降低了对大规模数据集的依赖。
计算资源分配方面,ATR机制通过路由网络动态决策关键标记,使得模型在4096序列长度下保持与基线相当的显存占用。具体实现中,路由网络采用门控机制生成0-1权重,选择权重超过阈值的标记进行额外思考步骤。这种选择性处理策略使推理速度相比全量处理提升约22%,同时保持模型输出的稳定性。
在可扩展性验证中,466M参数的ITT模型延续了性能优势,证明该架构具有跨规模普适性。研究人员特别指出,思考步骤数量与模型性能呈对数关系而非线性关系,当步骤数超过4时边际效益明显下降。这一发现为实际应用中的计算资源配置提供了重要参考依据。
原文和模型
【原文链接】 阅读原文 [ 1243字 | 5分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek-r1
【摘要评分】 ★★★☆☆


相关文章




