文章摘要
【关 键 词】 强化学习、数学推理、模型优化、开源资源、算法创新
上海AI Lab针对大语言模型在数学推理任务中面临的稀疏奖励困境、局部正确陷阱及规模依赖魔咒,提出了基于结果奖励的强化学习新范式OREAL。该框架通过正样本模仿学习、负样本偏好学习和关键步骤重点学习的三重策略,实现了无需依赖超大规模模型蒸馏的突破性进展。
研究团队发现,传统方法因二元反馈机制导致复杂推理优化困难,长思维链中局部正确步骤易引发误导,而模型规模军备竞赛加剧了资源消耗。基于理论推导,OREAL创新性地设计了正负样本差异化处理机制:对正确样本采用最佳轨迹采样(BoN)的行为克隆,对错误样本引入奖励重塑因子维持梯度一致性,并通过token重要性估计器实现结果奖励的因果溯源。这种细粒度奖励分配使模型能精准定位核心错误步骤,在GSM8K和MATH等数据集上验证了有效性。
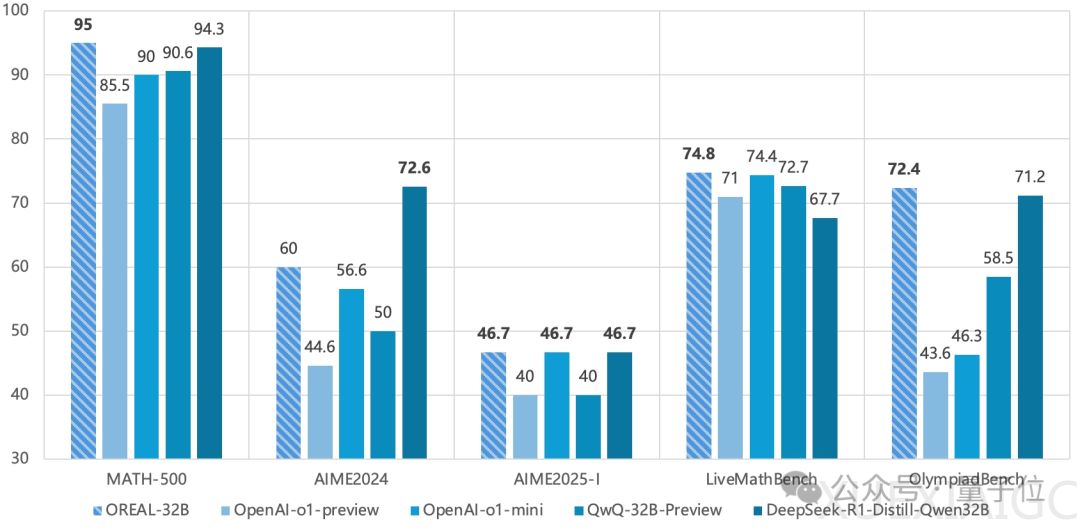
实验结果显示,OREAL在7B和32B模型规模上均取得显著提升。OREAL-7B以91.0%的pass@1准确率创下同规模模型新纪录,其增强版OREAL-DSR1-Distill-Qwen-7B更达到94.0%,刷新行业标杆。32B版本则以95.0%的准确率超越DeepSeek-R1-Distill-Qwen-32B,验证了算法在不同规模模型的普适性。值得注意的是,该方法仅需4000条高质量训练样本即实现性能突破,为资源效率树立新标准。
研究同时揭示了强化学习效果的关键影响因素:起点模型的质量与训练数据分布对最终性能具有决定性作用。在部分基准测试中出现的性能波动,可能与训练数据的覆盖度和难度梯度设计相关。为此,团队不仅开源了OREAL算法框架,还完整公开了训练数据、起点模型及优化后的模型参数。这种全流程开源策略有助于消除社区研究中变量干扰,推动强化学习技术的公平比较与持续创新。
该成果标志着中国团队在AI基础研究领域取得重要突破,首次证明强化学习可独立超越传统蒸馏方法,为打破参数规模竞赛提供了可行路径。未来研究方向将聚焦于训练数据质量优化与多模态推理任务拓展,持续探索大模型认知能力的边界。
原文和模型
【原文链接】 阅读原文 [ 1852字 | 8分钟 ]
【原文作者】 量子位
【摘要模型】 deepseek-r1
【摘要评分】 ★★★★☆


相关文章


