文章摘要
【关 键 词】 CLIP、Long-CLIP、图像检索、细粒度、多模态
上海交通大学与上海AI实验室合作提出了一种新的框架——Long-CLIP,旨在解决CLIP模型在处理长文本时的不足。CLIP模型通过对齐视觉和文本模态,具备强大的zero-shot泛化能力,广泛应用于多模态任务中。然而,CLIP在长文本处理方面存在限制,其文本输入长度被限制在77个token,有效长度不足20个token,这限制了其在细粒度任务中的应用。
为了克服这一限制,研究人员提出了Long-CLIP模型,并采用了两大策略:保留知识的位置编码扩充和加入核心属性对齐的微调策略。通过这些策略,Long-CLIP能够支持更长的文本长度,同时提升在各个任务上的性能。
在位置编码扩充方面,研究者们发现CLIP的不同位置编码训练程度不同,因此提出了一种策略,保留前20个位置编码,对剩余的位置编码以更大的比率进行插值。这种方法在支持更长文本的同时,显著提升了模型性能。
在微调策略方面,研究者们引入了核心属性对齐策略,通过主成分分析(PCA)算法从图像特征中提取核心属性,并与概括性的短文本进行对齐。这要求模型不仅能够包含更多细节,还能识别并建模最核心的属性。
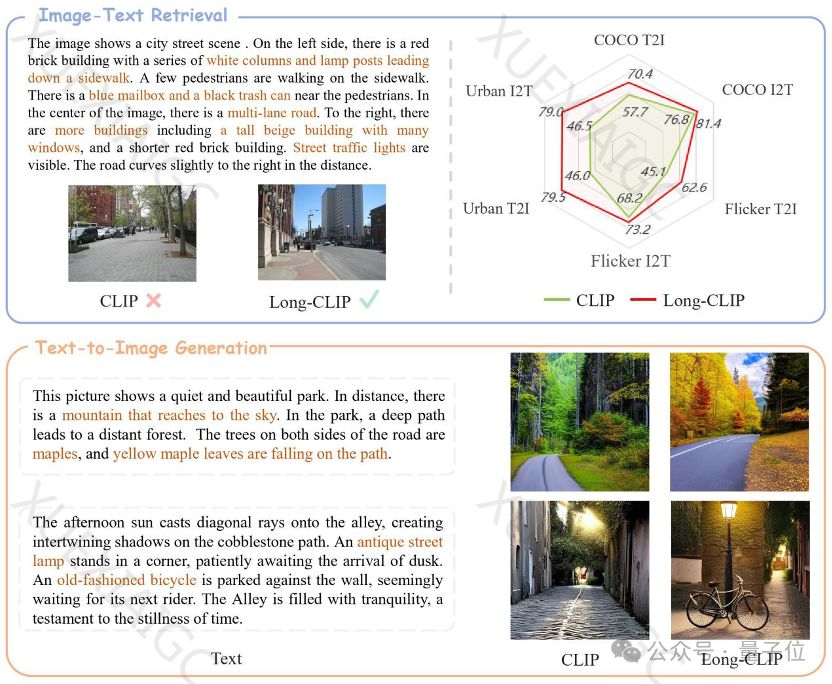
Long-CLIP在图文检索任务中表现出色,无论是短文本还是长文本检索任务,召回率都有显著提升。此外,Long-CLIP还能够用于图像生成任务,突破77个token的限制,实现篇章级别的图像生成,或在77个token内建模更多细节,实现细粒度图像生成。
总结来说,Long-CLIP通过扩展CLIP模型的长文本处理能力,显著提升了图像检索任务的性能,并能够在图像生成等下游任务中即插即用。这一进展不仅提升了多模态任务的细粒度处理能力,也为未来的研究和应用开辟了新的可能性。相关的论文和代码已经公开,供学术界和开发者进一步研究和应用。
原文和模型
【原文链接】 阅读原文 [ 1206字 | 5分钟 ]
【原文作者】 量子位
【摘要模型】 gpt-4
【摘要评分】 ★★★☆☆


相关文章


