一道题烧几千美元,OpenAI新模型o3:这34道题我真不会
文章摘要
【关 键 词】 AGI、推理模型、性能突破、计算成本、任务局限
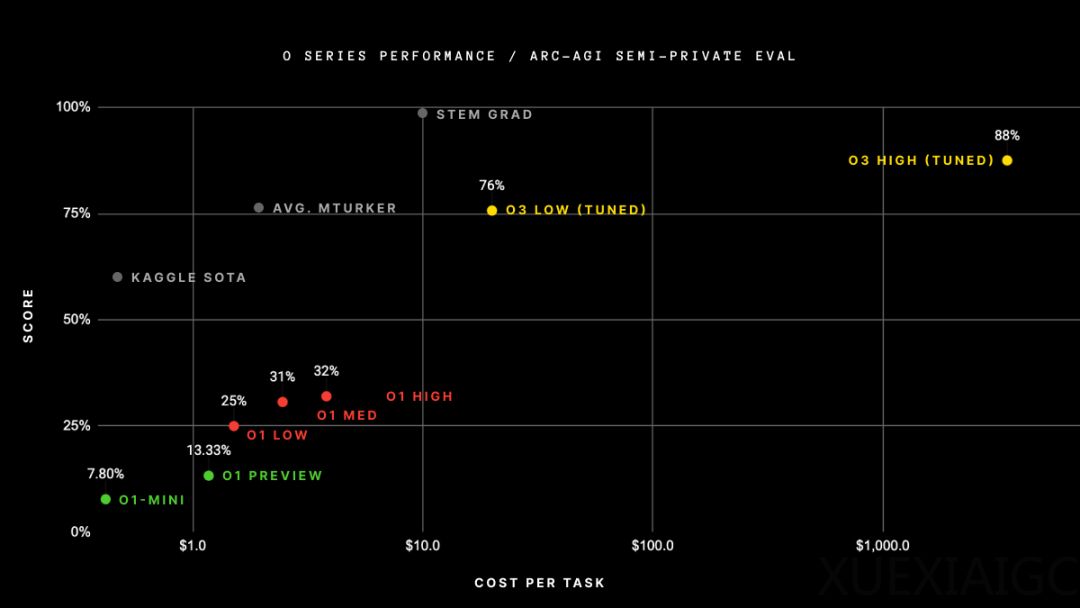
OpenAI最近推出了新的推理系列模型o3和o3-mini,这是自o1以来的第12次更新。这些模型基于OpenAI提出的推理Scaling Law,为实现人工通用智能(AGI)带来了新希望。o3模型在ARC-AGI基准测试中取得了突破,最低性能达到75.7%,而在更多计算资源的情况下,性能可提升至87.5%。相比之下,o1模型在该基准中的准确率仅为25%到32%。
ARC-AGI基准测试要求AI根据“输入-输出”示例寻找规律,并基于输入预测输出。Keras之父François Chollet在测试报告中指出,尽管成本高昂,但新任务的性能确实随着计算量的增加而提高。o3模型在低计算量模式下每个任务成本为17-20美元,而在高计算量模式下成本可达数千美元。这表明o3模型代表了人工智能适应新任务能力的重大飞跃,能够适应以前从未遇到过的任务,在ARC-AGI领域接近人类水平的表现。
然而,在ARC-AGI的400个任务中,仍有34个任务是o3无法解决的,即使思考了16小时也没能给出正确答案。Chollet认为,这表明o3与人类智能存在根本差异,还不是真正的AGI。o3在一些简单任务上仍然失败,这揭示了其局限性。
o3模型在某些任务中表现出了一维推理的局限性,例如在识别二维物体时遇到困难。Chollet指出,如果在第二次尝试时给大语言模型看旋转或翻转后的题目,它们的表现会明显提升。此外,o3在一些任务中漏掉了一些行或列,或者在答案中少生成了一行,显示出它在处理俄罗斯方块类型题目时的困难。
总的来说,o3模型在ARC-AGI基准测试中取得了显著进步,但仍存在一些局限性,特别是在处理某些简单任务和二维物体识别方面。这表明o3模型虽然在某些方面接近人类水平,但距离真正的AGI仍有差距。
原文和模型
【原文链接】 阅读原文 [ 1171字 | 5分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★☆☆☆


相关文章




