一图一3D世界,视频还可交互,昆仑万维「空间智能」开年首秀来了
文章摘要
【关 键 词】 空间智能、3D生成、交互视频、虚拟世界、AGI
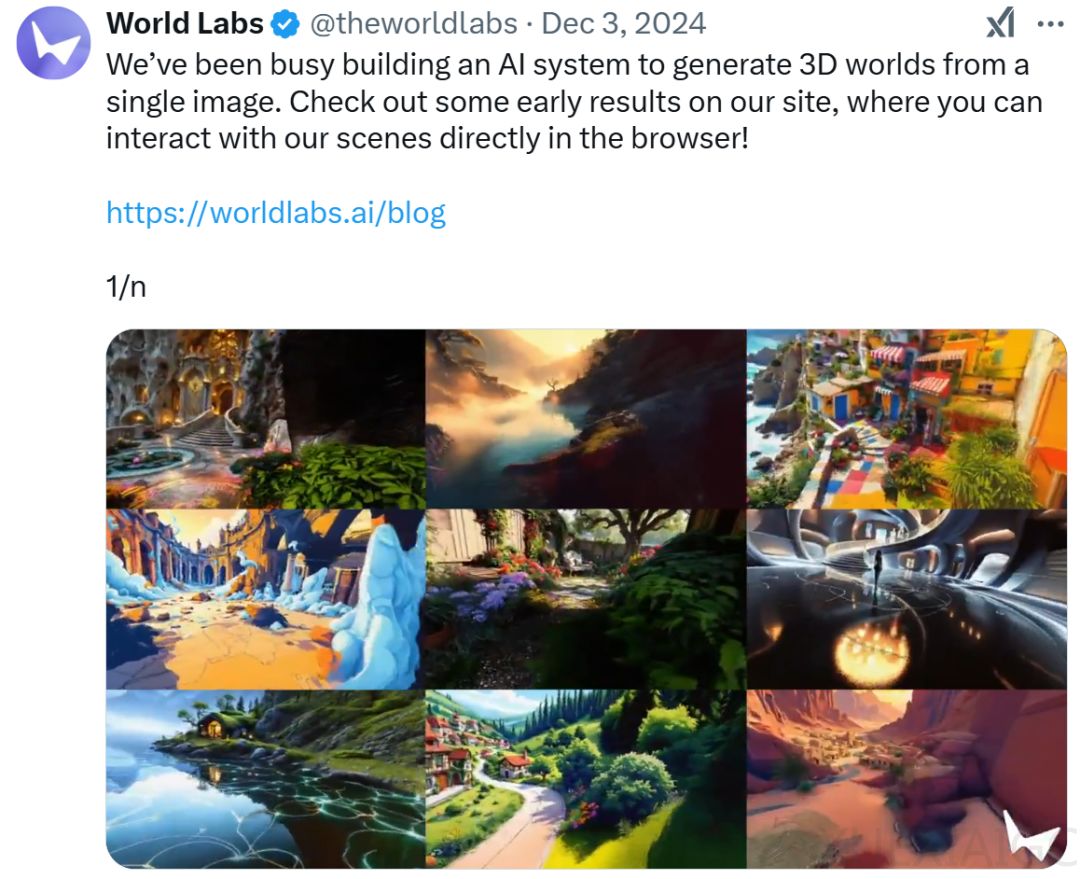
2025年被普遍视为智能体爆发元年,但空间智能领域正迎来突破性进展。昆仑万维发布的Matrix-Zero世界模型通过融合3D场景生成与可交互视频技术,将单张静态图像转化为可自由探索的3D虚拟世界,标志着国内企业在空间智能领域取得重要突破。该模型不仅支持风格转换和全局一致性生成,还能实现360度环视、复合移动等复杂交互操作,解决了传统3D生成中视角断裂与物理规则不符的难题。
技术层面,Matrix-Zero采用双模块架构:场景布局生成模块通过可微渲染和扩散模型构建空间结构,纹理生成模块结合3D高斯泼溅技术优化视觉细节。动态物理效果的实现依赖于深度学习与图形学融合,成功模拟水流、光照等自然现象,使生成场景具备真实物理属性。在可交互视频领域,模型通过Transformer架构和潜变量自编码器提升视频连贯性,用户输入交互模型则实现实时视角控制与运动轨迹调整,将视频生成从被动观看转变为主动探索。
相较于国际同类产品,Matrix-Zero展现出三大核心优势:一是支持输入图片风格继承与转换,覆盖写实与卡通等多种艺术形式;二是突破空间扩展限制,通过滑动窗口机制实现大范围场景的合理延伸;三是首创复合移动交互模式,允许用户执行前进后转向等复杂操作。这些技术进步为游戏开发、影视制作和具身智能训练提供了新工具。
从行业视角看,空间智能的突破正在重构AI发展路径。李飞飞团队与谷歌DeepMind的探索表明,理解三维空间关系是AI迈向通用智能的关键阶梯。昆仑万维通过构建”3D场景-交互视频”双模型架构,不仅完善了自身AI业务矩阵,更推动空间智能从理论研究走向工业应用。随着4月产品上线临近,其技术落地效果将直接影响行业对物理世界模拟能力的评估标准。
技术演进趋势显示,未来空间智能将向多模态感知方向发展。融合视觉、听觉、触觉的强化学习框架可能成为下一阶段重点,而实时物理仿真精度的提升将加速数字孪生、虚拟现实等领域的革新。对于All in AGI的企业而言,空间智能既是突破二维感知局限的技术跳板,也是构建通用世界模型不可或缺的认知基础。
原文和模型
【原文链接】 阅读原文 [ 4151字 | 17分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-r1
【摘要评分】 ★★★★★


相关文章



