文章摘要
【关 键 词】 人工智能、模型训练、数据集、推理能力、成本控制
斯坦福大学和华盛顿大学的研究人员开发了一个名为 s1 的人工智能推理模型,该模型以不到 50 美元的云计算成本成功训练而成,并在数学和编码能力测试中表现出与顶尖推理模型相当的水平。然而,深入分析揭示了一些误解和限制。
s1 模型的核心创新在于其构建的 s1K 数据集和预算强制法(budget forcing)。s1K 数据集包含 1,000 个经过精心挑选的问题,涵盖了数学竞赛、博士级科学问题和奥林匹克竞赛问题,并附有推理轨迹和答案。这些数据通过多个标准进行验证,确保难度、多样性和质量。研究团队使用谷歌的 Gemini Flash Thinking 模型生成每个问题的推理轨迹和答案。在测试时扩展方法上,团队关注顺序计算,并通过预算强制法控制模型的思考长度,防止过早结束推理或鼓励更多的探索。
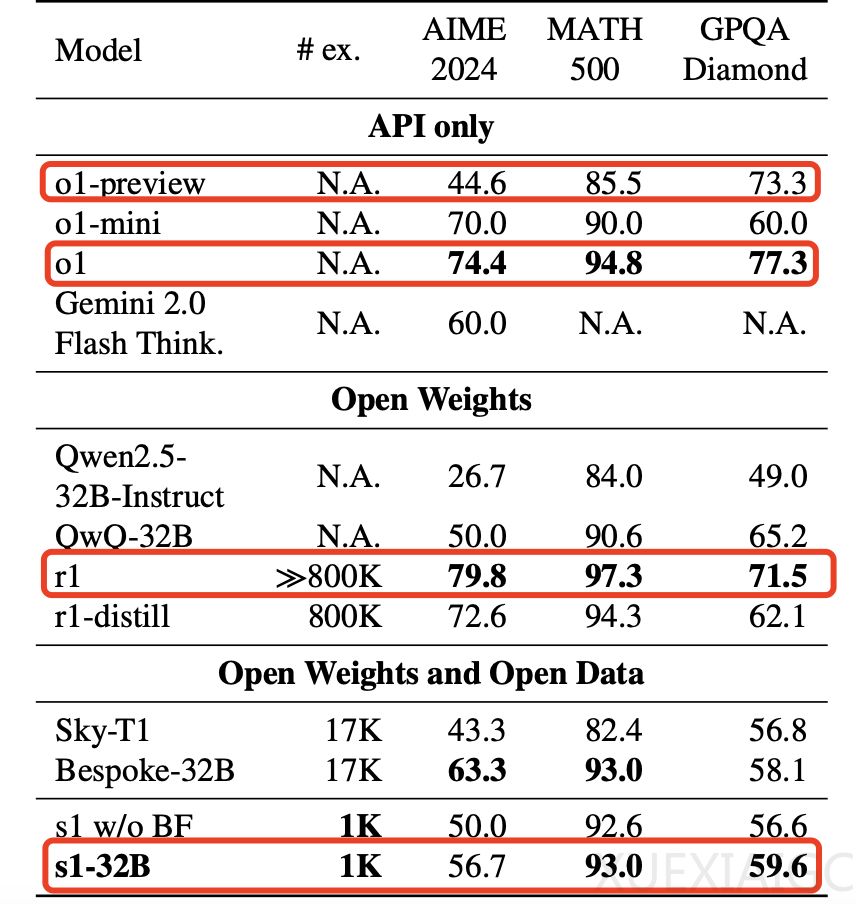
对于训练费用,仅限于微调阶段使用的 GPU 算力成本,确实可能低于 50 美元。但这一费用不包括数据准备、人力和其他实验环节的成本。并且 s1 并未超越 OpenAI o1 或 DeepSeek R1 的正式版,只是在特定测试集中优于 o1-preview。此外,尽管被描述为“蒸馏”自 Gemini,但实际上只是利用其生成的数据对 Qwen2.5-32B-Instruct 进行了监督微调,严格意义上并非传统意义上的知识蒸馏。
s1 的性能提升主要得益于高质量的训练数据和独特的预算强制技术。这种方法强制延长模型思考时间,促使模型生成更精确的答案。不过,s1 的性能表现仍然有限,仅能在特定领域如 AIME 和 MATH 基准上达到显著提升。另一个类似研究 LIMO 则进一步证实,通过少量高质量数据也可以显著提升复杂推理任务的表现。
尽管相关报道中强调了低训练成本和突破性性能,但实际成果并未达到颠覆行业标准的水平。部分传播过程中出现了过度简化的解读,导致对研究成果的误解。因此,虽然 s1 展现了低成本高效率训练的可能性,但距离全面媲美当前最先进模型还有一定差距。
原文和模型
【原文链接】 阅读原文 [ 2942字 | 12分钟 ]
【原文作者】 AI前线
【摘要模型】 qwen-max-2025-01-25
【摘要评分】 ★★★★★


相关文章




