文章摘要
【关 键 词】 DeepSeek、LiveCodeBench、AIME测试、国产AI、OpenAI
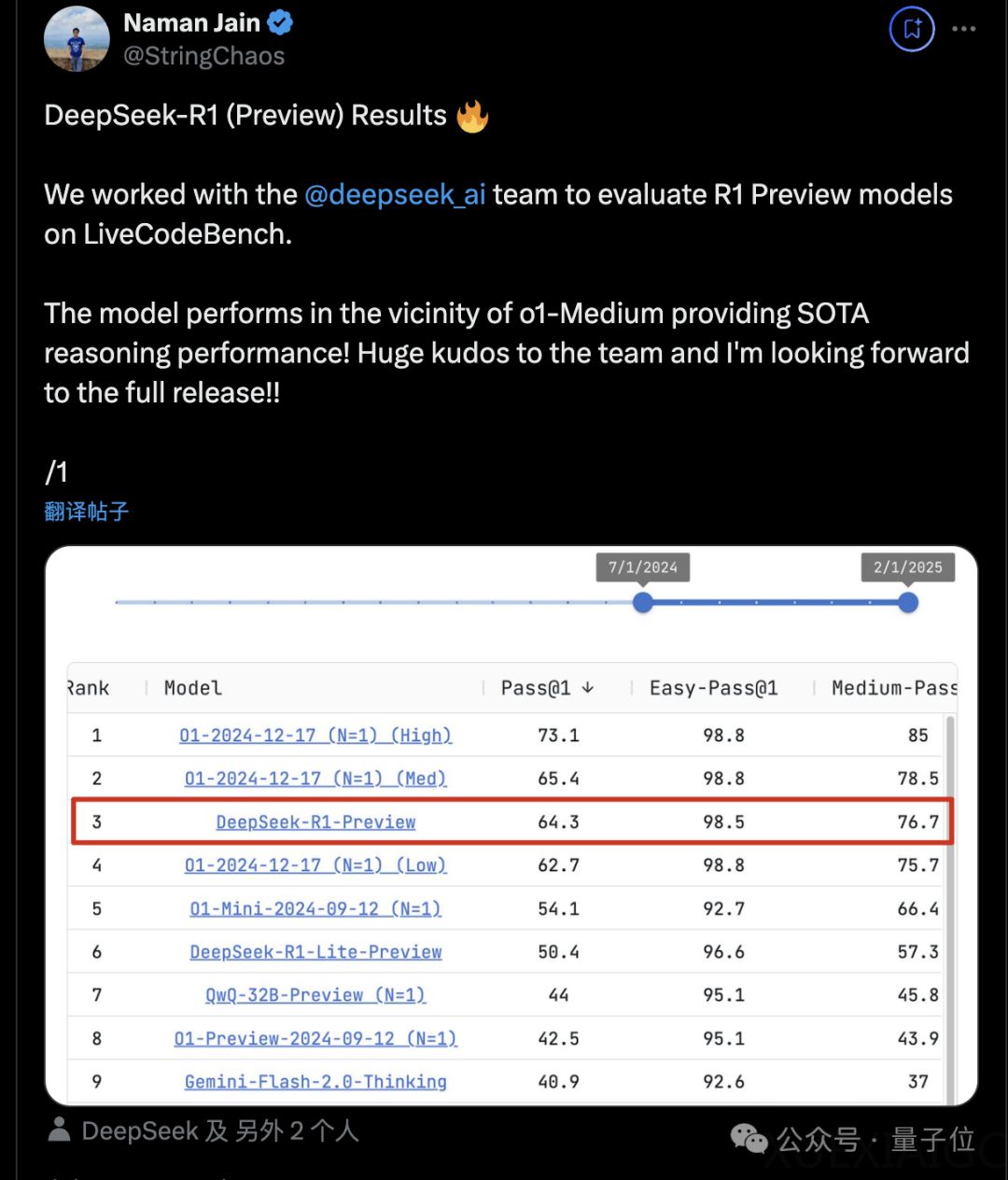
DeepSeek版o1,即DeepSeek-R1-Preview,尚未正式发布,已在LiveCodeBench代码基准测试中表现出色,位列前三,与OpenAI o1的中档推理设置相当。这一版本是DeepSeek-R1-Lite-Preview的升级,使用了更大规模的基础模型。LiveCodeBench团队与DeepSeek合作,评估新模型的能力,并在合作过程中解决了评分系统的一些bug。DeepSeek-R1-Preview的思考过程也被展示出来,引发了网友对开源模型和API的期待。
DeepSeek-R1-Lite-Preview使用强化学习训练,推理包含大量反思和验证,遵循新的Scaling Laws,即推理越长,表现越强。在AIME测试基准中,随着推理长度的增加,DeepSeek-R1-Lite-Preview表现出稳定的得分提升。在某些情况下,模型似乎能够在生成推理步骤时自我纠正,表现出类似原生“自我反思”的能力。
LiveCodeBench由UC伯克利、MIT和康奈尔大学团队推出,旨在对大模型的代码能力进行全面且无污染的评估。测试方法实时更新,确保公平性和可靠性,获得了开发者社区的认可。
春节前,多个国产大模型团队更新了自家模型,包括MiniMax开源4M超长上下文新模型、国产AI开源端侧GPT-4o、讯飞版o1以及阿里开源首个视觉推理模型。OpenAI似乎也在假期期间有所动作,o3-mini完成外部合作测试,已确定最终版,将在几周内推出,会同时上线API和ChatGPT。未来模型的基本情况也得到了确认,包括o3-mini的速度、性能、收费情况以及OpenAI对AI一次性输出更多内容的关注,以及2025年计划将GPT系列和o系列合并。

原文和模型
【原文链接】 阅读原文 [ 896字 | 4分钟 ]
【原文作者】 量子位
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★☆☆☆☆





