文章摘要
面壁智能最近发布了全新一代小钢炮MiniCPM-o 2.6,这是一款端到端模型,参数规模为8B,在视觉、语音和多模态方面与GPT-4o-202405性能相当。MiniCPM-o 2.6支持双语实时语音对话,具备声音可配置性,能够控制情绪、语速和风格,实现端到端语音克隆和角色扮演等功能。在视觉能力上,该模型提升了OCR能力、可信行为、多语言支持和视频理解。由于其优越的token密度,MiniCPM-o 2.6首次支持在iPad等端侧设备上进行多模态实时流。
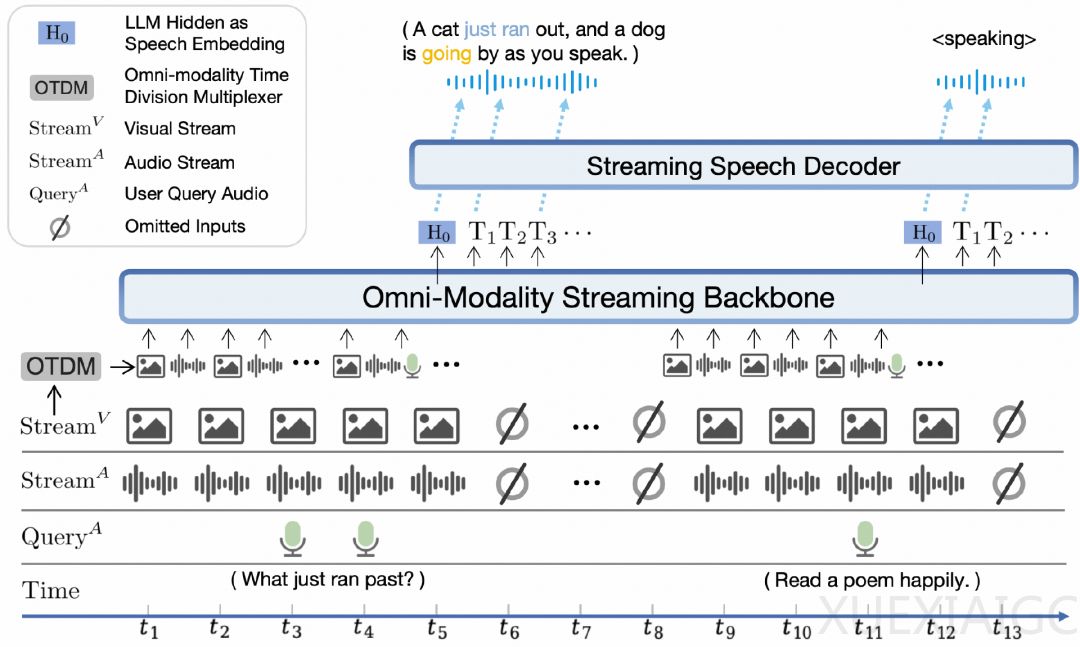
MiniCPM-o 2.6采用了端到端全模态架构,不同模态编码器/解码器以端到端方式连接和训练,以充分利用多模态知识。该模型还设计了时分复用(TDM)机制,用于LLM主干中的全模态流处理,以及可配置语音建模设计,包括文本和音频系统提示,以确定助手语音,实现推理时间内的灵活配置。
面壁智能的评估显示,MiniCPM-o 2.6在实时流式全模态开源模型中取得SOTA,性能与GPT-4o、Claude-3.5-Sonnet相当。在语音方面,该模型在理解和生成方面均取得开源双SOTA,成为最强开源语音通用模型。在视觉领域,MiniCPM-o 2.6也保持了最强端侧视觉通用模型的地位。
MiniCPM-o 2.6在实时流式视频理解能力上与GPT-4o、Claude 3.5 Sonnet相当,在语音理解方面超越Qwen2-Audio-7B-Instruct,实现通用模型开源SOTA,包括ASR、语音描述等任务。在语音生成方面,MiniCPM-o 2.6超越GLM-4-Voice 9B,实现通用模型开源SOTA。
面壁智能强调,MiniCPM-o 2.6能够感知用户提问之前的画面和声音,并持续对实时视频和音频流进行建模,这种方式更贴近人眼的自然视觉交互。此外,MiniCPM-o 2.6能听懂GPT-o听不到的背景声音,如翻书、倒水、敲门声等,且具备实时打断不迷糊的能力。
面壁智能认为,端侧大模型具有隐私性好、更可靠、响应快、不惧弱网断网环境等优势,且具有更早、更快落地的潜力。MiniCPM-o 2.6的视、听、说全模态特性,在端侧具有巨大潜力,如智能座舱、教育和商务场景中的应用。面壁团队还提出了大模型密度定律,预测模型能力密度随时间呈指数级增长,实现相同能力的模型参数每3.3个月下降一半,模型推理开销和训练开销随时间指数级下降。
原文和模型
【原文链接】 阅读原文 [ 2059字 | 9分钟 ]
【原文作者】 AI前线
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章



