文章摘要
【关 键 词】 GPT模型、性能波动、指令遵循、代码生成、行为动态
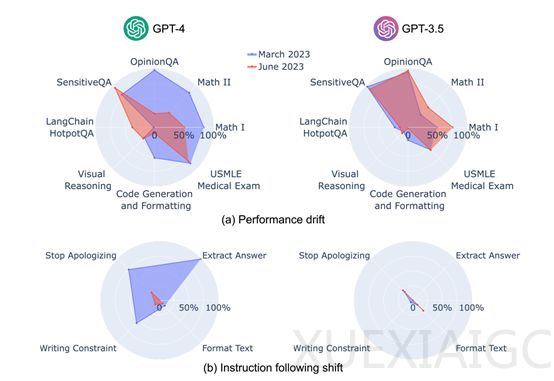
斯坦福大学和加州伯克利大学的研究人员在《哈佛数据科学评论》上发表的论文《ChatGPT行为随时间变化》中,对GPT-3.5和GPT-4模型在不同时间点的性能和行为进行了深度分析。研究涵盖了数学问题、代码生成、多跳知识密集问答等七项任务,结果显示GPT-3.5和GPT-4在三个月内性能和行为出现了显著波动。GPT-4在3月份能以84%的准确率区分质数与合数,但到了6月份准确率下降至51%,部分原因是其遵循“思维链”提示的能力减弱。与此同时,GPT-3.5在同一时期的表现却有所提升。
研究还发现,GPT-4在6月份对敏感问题和意见调查的回应意愿降低,而在解答需要多步推理的问题上表现更好,而GPT-3.5在这类任务上表现下滑。两个模型在代码生成方面的格式错误均有所增加,且GPT-4遵从用户指令的能力呈现下降趋势。
研究人员基于多样性和代表性原则,设计了一套新的基准测试,专注于任务无关的指令遵循度,包括答案提取、停止道歉、避免特定词汇和内容过滤等四种常见指令类型。GPT-4在3月时能较好地遵循大多数个体指令,但在6月则开始忽视这些指令,例如,回答提取指令的遵循率从99.5%骤降至接近零,内容过滤指令的忠实度也从74.0%下降到19.0%。
此外,研究团队为每个任务设定了主要的性能指标和通用的补充指标,如数学问题和USMLE使用准确性作为主要指标,代码生成以输出代码的可执行比例为主。研究结果表明,GPT-4在处理明确指令格式上的退化,可能反映了模型内部更新或训练策略的调整,导致其在理解和执行具体格式要求时的不一致。
研究人员指出,由于GPT-3.5和GPT-4都是闭源模型,OpenAI不会公开其详细的训练数据和流程,因此每次发布大版本更新时,用户无法知道哪些功能发生了较大变化。本研究有助于开发人员和用户了解ChatGPT的性能、行为动态,这对于确保模型的安全性、内容真实性至关重要。

原文和模型
【原文链接】 阅读原文 [ 1485字 | 6分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★☆☆





