文章摘要
【关 键 词】 视觉Agent、AI框架、微软技术、模型解析、开源工具
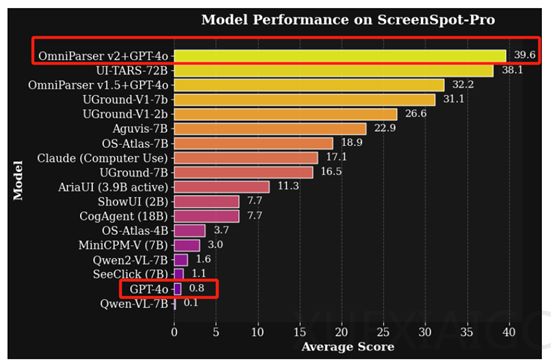
微软近期发布了视觉Agent解析框架OmniParser的最新版本V2.0,该框架可将DeepSeek-R1、GPT-4o等大语言模型转化为可在计算机上运行的AI Agent。相比V1版本,V2在检测小型可交互UI元素时准确率显著提升,推理速度加快且延迟降低60%。在高分辨率Agent基准测试ScreenSpot Pro中,V2与GPT-4o结合的准确率达到39.6%,而GPT-4o单独使用时准确率仅为0.8%,显示出技术突破性进展。
为支持开发者生态,微软同步开源了集成工具omnitool,其包含三大核心组件:OmniParser V2、OmniBox轻量级Windows 11虚拟机及Gradio交互界面。其中,OmniBox通过Docker实现系统部署,磁盘空间占用较传统虚拟机减少50%,同时提供完整的计算机操作API,使开发者在有限硬件资源下也能高效搭建GUI自动化测试环境。Gradio UI则简化了交互流程,支持通过浏览器直接验证自动化任务效果。
OmniParser V2的核心创新在于将用户界面从像素空间转化为结构化元素,类比自然语言处理中的分词技术。通过“标记化”解析,大模型可精准识别按钮、输入框等交互元素,并关联其功能语义。例如,网页中的“三个点图标”被解析为“更多选项入口”,而放大镜图标则对应“搜索功能”。这种结构化理解使模型能更准确地规划动作序列,如点击登录按钮或输入关键词。
技术实现上,框架采用多阶段解析流程。首先通过深度学习模型检测可交互区域,其训练数据涵盖67,000张标注网页截图,确保元素定位精度。随后,功能语义模块利用微调的BLIP-v2模型,将图标特征转化为功能描述,例如将圆形图标定义为“设置菜单入口”。微软为此构建了包含7,185个图标-描述对的专业数据集,显著提升语义解析的实用性。最终,结构化表示模块整合边界框、唯一ID及语义信息,生成类DOM的UI表征,帮助大模型聚焦动作预测。
开源生态方面,OmniParser V2及omnitool已在Hugging Face和GitHub平台发布。工具链的设计强调易用性与扩展性,开发者可通过组合不同模块快速实现从屏幕理解到动作执行的完整Agent工作流。该技术不仅适用于网页操作自动化,也为复杂软件界面的智能交互提供了新的技术路径。
原文和模型
【原文链接】 阅读原文 [ 1515字 | 7分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek-r1
【摘要评分】 ★★★☆☆


相关文章




