人机协同筛出2600万条数据,七项基准全部SOTA,昆仑万维开源奖励模型再迎新突破
文章摘要
【关 键 词】 大语言模型、奖励模型、强化学习、开源模型、数据构建
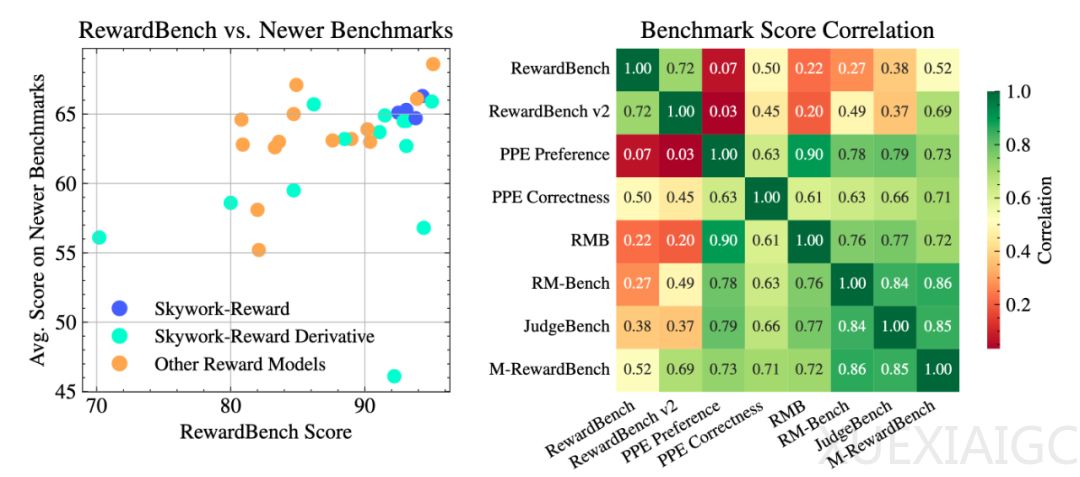
大语言模型(LLM)的生成能力虽然强大,但其输出是否符合人类偏好需要依赖奖励模型(Reward Model, RM)的精准评判。奖励模型在大模型训练中扮演着关键角色,它通过打分机制引导模型生成更符合人类价值观的内容。昆仑万维近期发布的Skywork-Reward-V2系列模型,在七大主流评测榜单上均取得第一,标志着奖励模型技术的新突破。该系列包含8个不同参数规模的模型,从6亿到80亿不等,展现出广泛的适用性和卓越的性能。
奖励模型面临的核心挑战在于如何平衡评判准确性、通用性和灵活性。当前开源奖励模型普遍存在过度优化和过拟合问题,难以捕捉人类偏好的复杂性。为解决这一问题,昆仑万维创新性地构建了包含4000万对偏好样本的Skywork-SynPref-40M数据集,采用”人机协同、两阶段迭代”的数据甄选流程。第一阶段通过人工标注”黄金数据”和模型生成”白银数据”相结合的方式突破初始瓶颈;第二阶段则完全由奖励模型进行自动化筛选,最终精选出2600万条高质量数据。
数据质量的提升显著缩小了模型参数规模与性能之间的差距。在RewardBench v2基准测试中,仅0.6B参数的Skywork-Reward-V2-Qwen3模型就接近了上一代27B参数模型的性能,而8B参数的版本更是超越了70B级别的开源SOTA模型。实验证明,仅使用29万条精选数据训练的8B模型,其性能就已超过当前70B级的最优奖励模型,验证了”少而精”数据策略的有效性。
Skywork-Reward-V2在多项专业评估中展现出全面优势。在JudgeBench知识密集型任务上,其数学表现达到与OpenAI o3-mini同等水平;在PPE Correctness评估中,全系模型在有用性和无害性指标上超越GPT-4o,最高领先达20分。此外,该系列模型在偏见抵抗能力测试(RM-Bench)和复杂指令理解(RewardBench v2)等评估中也取得领先,显示出强大的泛化能力。
昆仑万维的开源策略加速了大模型技术迭代。除奖励模型外,该公司还开源了包括代码智能体基座模型、空间智能模型、多模态推理模型等多个领域的SOTA模型。这种大规模开源行为不仅推动了技术民主化,也为整个AI社区提供了宝贵的研究资源。随着数据构建本身成为一种建模行为,未来RLHF技术可能会朝着更高效的数据驱动对齐方向发展,而人机协同的数据生产方式将为这一进程提供重要支撑。
原文和模型
【原文链接】 阅读原文 [ 3244字 | 13分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章




