原文作者:AIProall
作者简介:AI工具分享,AI应用实操教程、落地商业应用案列拆解及行业应用解决方案。
微信号:AichatGPTone
关键词:视频编辑、技术细节、时间一致性、内存优化、局限性
文章摘要:这篇文章详细介绍了VidToMe视频编辑工具,这是一个由上海交通大学和加州大学默塞德分校研究团队共同发布的产品。VidToMe利用增强的预训练图像扩散模型来提高视频编辑的时间一致性和质量,但不支持从文本或图像生成视频的功能。
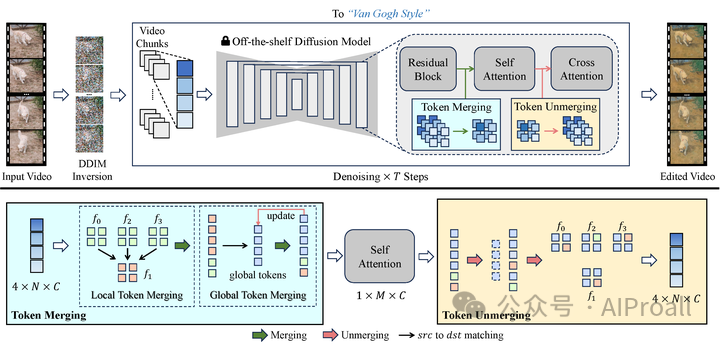
VidToMe产品的框架及技术细节
VidToMe通过合并视频帧中的自注意力标记来增强视频的时间一致性。它采用了以下步骤来编辑视频:
1. 使用DDIM逆向处理将视频帧转换为噪声。
2. 应用扩散模型处理去噪,并保持源帧结构。
3. 将帧分割成块,并在块内进行局部标记合并。
4. 维护全局标记以实现长期内容一致性。
5. 分析自注意力操作在合并标记上的表现。
6. 展开标记以进行后续图像操作。VidToMe产品的主要功能和作用
VidToMe的主要功能包括:
1. 增强时间一致性:通过合并标记,使视频帧在时间上更连贯。
2. 优化内存消耗:减少自注意力计算中所需的内存量。
3. 扩展视频编辑:将图像编辑技术应用于视频编辑。
4. 提供灵活性和控制:允许用户通过不同的控制信号来指导视频编辑。
5. 提升性能:在时间一致性和文本对齐方面优于现有方法。VidToMe的评估结果
VidToMe在多个评估指标上进行了测试,包括时间一致性和文本对齐,并与其他基线方法进行了比较。结果显示,VidToMe在时间一致性和文本对齐方面表现出色,用户偏好率也最高。VidToMe方法的局限性
VidToMe的局限性主要体现在:
1. 依赖于图像编辑技术的性能:编辑能力受限于图像编辑技术。
2. 相似性匹配的准确性问题:可能会出现不准确的标记合并情况。为了克服这些局限性,未来的工作可能会探索更精确的标记匹配方法,并改进图像编辑技术,以提供更可靠和高质量的视频编辑结果。
原文链接:阅读原文
原文字数:2181
阅读时长:8分钟

相关文章




