文章摘要
【关 键 词】 大模型训练、深度诅咒、层归一化、模型剪枝、梯度优化
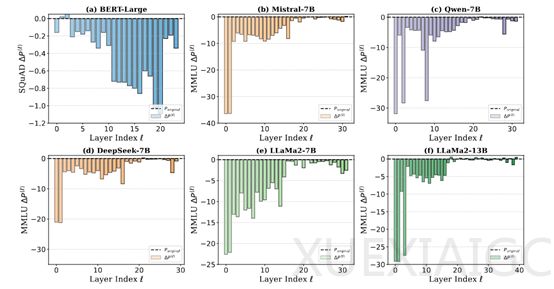
近年来,高性能大模型的训练面临深层网络效率低下的难题。研究表明,以DeepSeek、Qwen、Llama和Mistral为代表的模型在训练过程中,深层网络对整体性能的贡献显著低于预期。实验数据显示,移除DeepSeek-7B模型的深层结构对性能影响微乎其微,而浅层结构的剪枝则会导致明显性能下降,这种现象被定义为”深度诅咒“。
深度诅咒的根源与Transformer架构中广泛采用的Pre-LN(前置层归一化)技术密切相关。Pre-LN在稳定训练过程的同时,导致深层网络输出方差呈指数级增长,使得深层Transformer块的导数趋近单位矩阵。这种数学特性造成深层网络在训练中几乎无法学习有效特征,反而形成近似恒等映射的无效结构。这不仅造成数千GPU月级别的算力浪费,更严重制约了模型性能提升和规模扩展的潜力。
针对这一挑战,研究团队提出LayerNorm Scaling创新方案。该技术通过引入与网络深度相关的动态缩放因子,实现对各层输出方差的精准调控。具体而言,浅层采用较大缩放因子保持特征强度,深层则通过平方根倒数缩放因子抑制方差累积。这种调节机制被形象比喻为对”高楼能量输出”的分层控制,既维持浅层特征提取能力,又避免深层梯度爆炸。
实验验证显示,LayerNorm Scaling在多个量级模型上均取得显著效果。在预训练阶段,LLaMA-130M模型困惑度从26.73降至25.76,十亿参数模型的困惑度降幅达1.31。监督微调阶段,LLaMA-250M在ARC-e任务上提升3.56%,平均性能增益达1.8%。当应用于DeepSeek-7B时,深层网络的学习参与度显著提升,困惑度下降曲线更趋稳定。
该研究突破性地揭示了大规模语言模型训练中的结构效率瓶颈,提出的解决方案不仅提升现有模型训练效率,更为千亿级以上超大模型的优化提供了新思路。通过数学建模与工程实践的结合,LayerNorm Scaling成功打通了深度网络梯度传播通道,使深层结构真正发挥理论预期的性能优势。相关成果已通过论文公开发表,为行业提供了可复现的技术路径。
原文和模型
【原文链接】 阅读原文 [ 1651字 | 7分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 deepseek-r1
【摘要评分】 ★★★★☆


相关文章



