阶跃公开了自家新型注意力机制:KV缓存消耗直降93.7%,性能不减反增
文章摘要
【关 键 词】 注意力机制、多矩阵分解、内存优化、性能提升、Transformer生态
近期,阶跃星辰与清华大学等机构合作的论文《Multi-matrix Factorization Attention》提出了一种新型注意力机制架构——多矩阵分解注意力(MFA)及其变体MFA-Key-Reuse。这项研究针对大语言模型在推理时面临的内存挑战,特别是传统注意力机制中的键值缓存(KV Cache)随着批处理大小和序列长度线性增长的问题,提出了解决方案。MFA和MFA-KR在大幅降低语言模型推理成本的同时,实现了性能的显著提升。
研究团队通过分析Attention机制的一般性设计和容量,提出了广义多头注意力(GMHA)的概念框架,为理解不同的MHA变种提供了统一视角。他们还确立了完全参数化双线性注意力(FPBA)作为理论上的性能上限标准,并分析了现有解决方案如多查询注意力(MQA)和多头潜在注意力(MLA)的局限性。
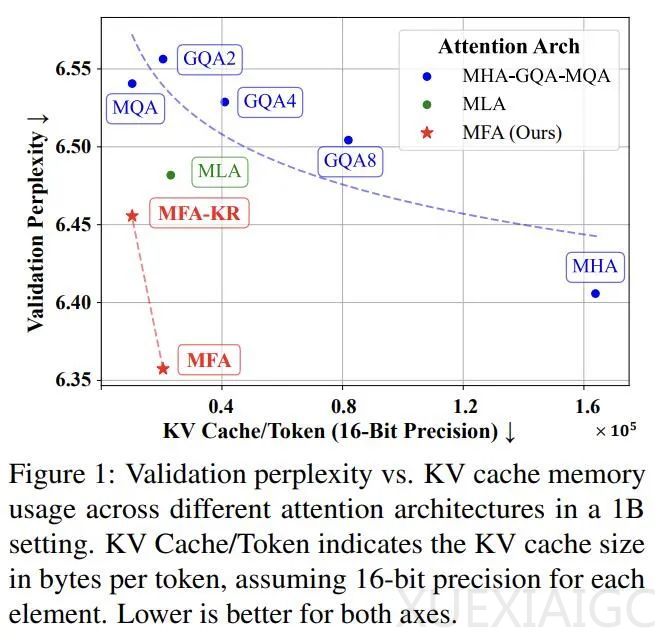
MFA的设计体现了三个关键创新:突破传统设计的局限,增加注意力头的数量和维度;在矩阵分解方面实现创新性突破,采用激进的低秩分解策略;采用单键值头设计,确保内存使用保持在最低水平。实验结果显示,MFA和MFA-KR在减少高达93.7%的KV Cache使用量的同时,与传统的MHA性能相当。
研究团队还开展了深入的扩展性实验,测试了从1B到7B参数的不同规模模型,发现MFA方案展现出与传统MHA相当的扩展能力。在最大规模模型上,MFA实现了87.5%的内存节省,而MFA-KR将内存使用降低到原来的6.25%。消融实验进一步证明了MFA和MFA-KR设计的有效性,并在其他主流位置编码上验证了性能优势。
这项研究用简洁的设计带来了显著提升,优雅地解决了大语言模型的高效推理显存瓶颈问题,能无缝集成到现有Transformer生态中,有望加速大语言模型在更多场景的落地应用。
原文和模型
【原文链接】 阅读原文 [ 2061字 | 9分钟 ]
【原文作者】 机器之心
【摘要模型】 moonshot-v1-32k
【摘要评分】 ★★★★★


相关文章


