文章摘要
【关 键 词】 边缘计算、AI推理、GPU架构、能效优化、软硬件协同
在人工智能推理逐渐向边缘计算转移的背景下,Imagination推出了全新的E系列GPU IP,旨在通过“AI+图形”深度融合的架构,满足边缘设备对低功耗、高灵活性和强算力的多重需求。这一创新架构通过算力扩展、功耗优化和软件生态配套,重新定义了边缘AI计算的边界,并为行业提供了一条兼顾灵活性与高效性的技术路径。
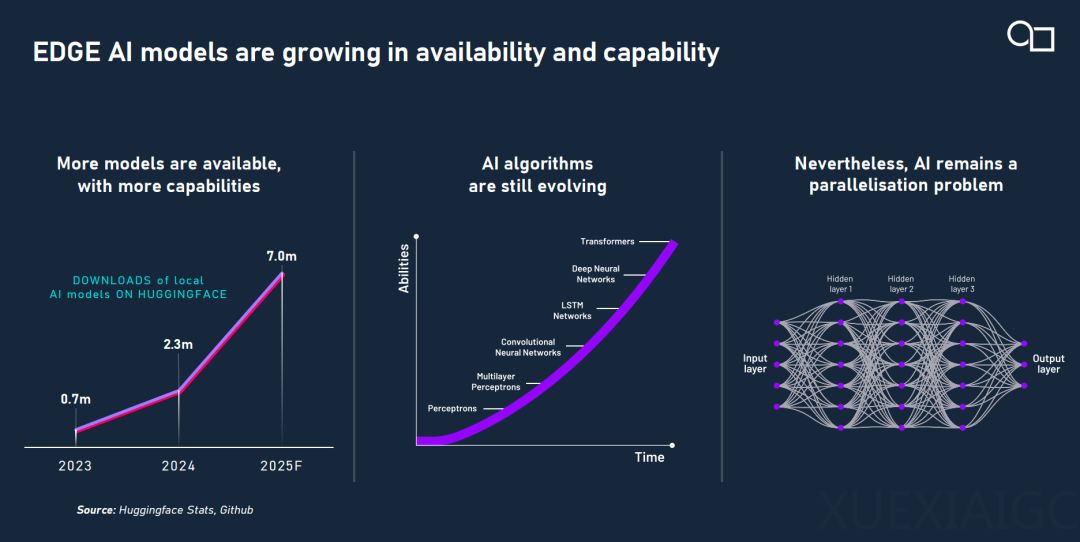
边缘AI的快速发展推动了GPU的转型。当前,自动驾驶、智能手机、工厂设备等应用场景逐渐脱离云端,开始在本地完成图像识别、路径规划等任务。Imagination中国区技术总监艾克指出,边缘AI需求的爆发主要源于隐私敏感数据无法上云、实时性要求以及边缘设备的资源限制。AI模型的快速迭代,特别是从卷积神经网络到Transformer的转变,对硬件的灵活性和并行计算能力提出了更高要求。传统处理器架构在应对这些需求时各有优劣,而Imagination的E系列GPU IP则在灵活性与通用加速能力之间找到了平衡。
E系列GPU的最大亮点在于其“AI+图形”深度融合的架构设计。Imagination通过分块延迟渲染技术、压缩缓冲等图形处理技术,将AI加速能力原生嵌入GPU体系,使其从图形引擎演进为通用AI处理核心。E系列在相同工艺节点下比前一代实现了35%的平均能效提升,这得益于其引入的爆发式处理器技术,通过指令调度路径压缩、本地寄存器复用机制和矩阵乘法运算单元的集成优化,显著提升了系统稳定性和灵活性。与NPU相比,E系列不仅具备更高的可编程性与灵活性,还具备面向未来模型演进的架构适应能力,尤其适合图形增强类AI场景。
在算力层面,E系列支持从轻量级终端到复杂多模态系统的全场景部署,其神经核支持2TOPS至200TOPS的AI算力覆盖,单位面积下的算力密度比前代提升了3.6倍。同时,E系列支持多种AI主流格式,结合Imagination优化的计算库与图优化编译器,开发者可通过TVM等框架便捷地完成主流模型的部署与适配。在任务调度层面,E系列支持多达16个虚拟机实例的运行隔离,能够实现AI、图形、UI等多任务的异步并行处理,尤其在车载场景中展现出良好的适配能力。
软硬件协同是边缘AI落地的关键。Imagination为E系列配套构建了完整的软件栈支持,包括数学计算库、FFT、Kernel优化、TVM适配等,开发者不仅能完成离线模型部署,还能实现轻量级应用的在线部署及推理推送。此外,Imagination在RISC-V生态中也扮演着关键角色,推动开源硬件与高效算力在边缘智能中的协同演进。
E系列GPU IP的推出标志着Imagination技术积淀的里程碑,不仅在性能、功耗和芯片面积上实现突破,更通过架构创新,从传统图形渲染迈向通用AI计算。面对边缘AI应用的爆发式增长,E系列以图形渲染与AI推理的统一计算平台,为客户提供了更高灵活性与竞争力。随着首款E-Series GPU IP将于2025年秋季正式上市,这一系列产品有望在中国市场掀起一轮边缘算力升级的新热潮。
原文和模型
【原文链接】 阅读原文 [ 2478字 | 10分钟 ]
【原文作者】 半导体行业观察
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★★


相关文章




