超越DeepSeek-R1关键RL算法GRPO,CMU「元强化微调」新范式登场
文章摘要
【关 键 词】 大模型、推理优化、元强化学习、测试计算、效率提升
大语言模型(LLM)在推理领域的最新进展表明,通过扩展测试时计算可以显著提升模型的推理能力。OpenAI的o1系列等模型展示了这一潜力,尤其是在生成长推理链时,模型能够通过反思、规划或线性搜索等“算法”行为来提高准确性。然而,尽管通过结果奖励强化学习(RL)生成长推理链的方式前景看好,但仍需解决一些关键问题,例如当前LLM是否高效使用了测试时间计算,以及当测试时token预算远大于训练预算时,模型是否能够发现更难问题的解决方案。
为了应对这些挑战,CMU和HuggingFace的研究者提出了一种新的方法,即从元强化学习(RL)的视角来优化测试时计算。该方法的核心是将LLM的输出流分割成多个片段,并在每个片段中平衡探索与利用。传统的RL目标是学习一个固定的策略,而这里的元RL目标是学习一个能够在每个测试问题上动态调整探索与利用的算法。这种方法的理想状态是在过早采用一种方法和尝试过多高风险策略之间取得平衡,从而最小化输出token预算的累积悔值。
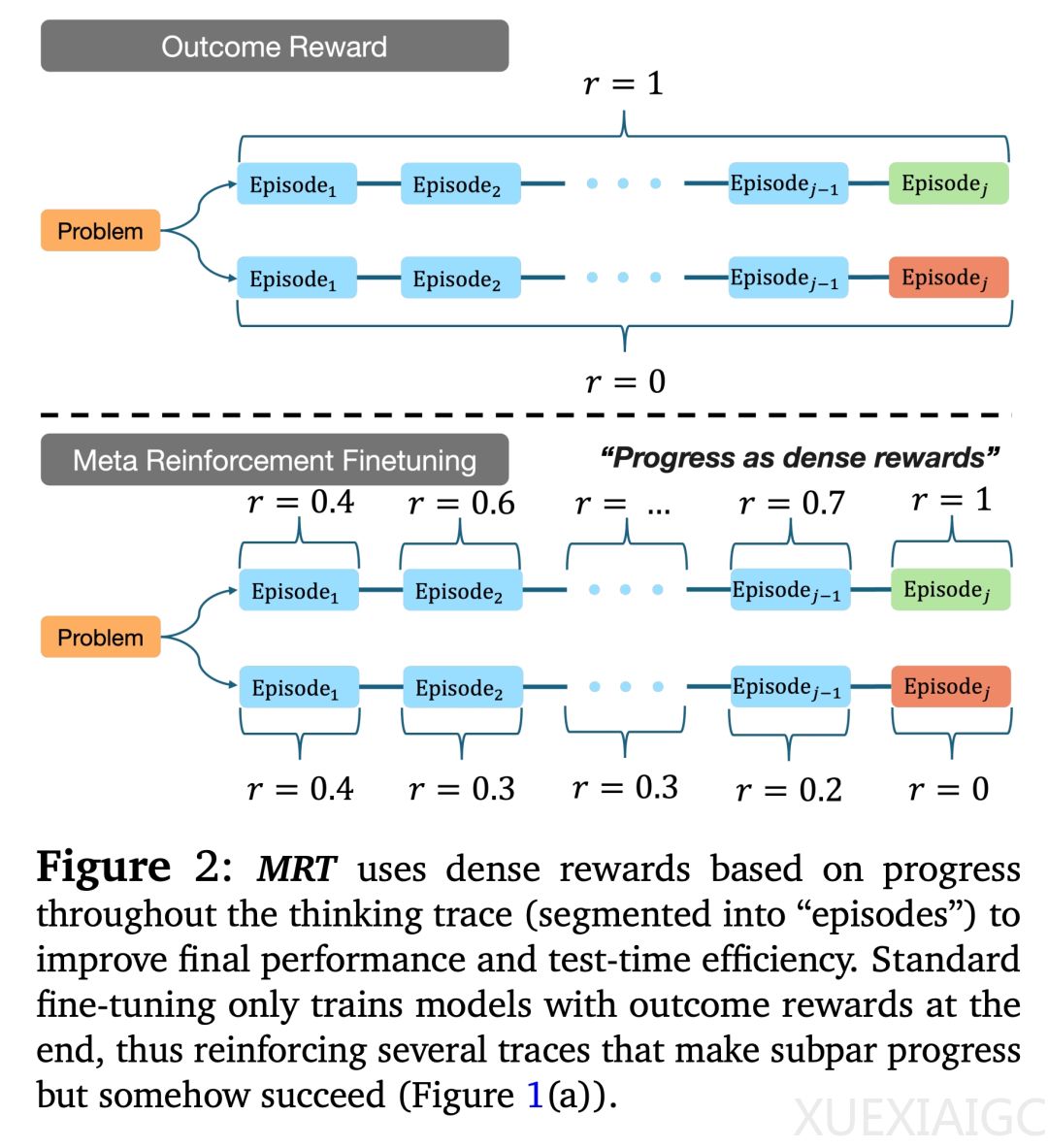
研究者提出了一种名为元强化微调(Meta Reinforcement Fine-Tuning,MRT)的范式,通过最小化累积悔值来优化测试时计算。MRT的核心思想是训练LLM在生成每个token时都能获得足够的效用,从而提高效率并形成系统化的流程来解决分布外问题。实验表明,使用结果奖励RL进行微调的现有LLM无法通过更多片段来提高发现正确答案的概率,而MRT则显著提升了模型的性能。
在实验中,研究者对DeepScaleR-1.5B-Preview、DeepSeek-R1-Distill-Qwen-1.5B和DeepSeekR1-Distill-Qwen-7B等模型进行了微调,并在多个数学推理问题数据集上进行了评估。结果显示,MRT在多个基准测试上取得了15亿参数规模的SOTA结果,其准确率提升是标准结果奖励RL(GRPO)的2-3倍,而token效率是GRPO的1.5倍、基础模型的5倍。此外,MRT在Llama 3.1模型上的微调也实现了1.6-1.7倍的token效率提升。
MRT的独特之处在于它直接学习了一种与预算无关的LLM,使其能够稳步取得进展。通过在线强化学习方法,研究者定义了一个元证明器策略,用于评估每个片段对解决问题的贡献程度。在训练过程中,MRT优化了包含标准结果奖励和基于进展的密集奖励的目标函数,从而显著提升了模型的推理效率和准确性。
实验结果表明,MRT不仅在AIME 2024和AIME 2025评估集上取得了更好的性能,而且在分布外的AMC 2023数据集上也保持了较好的性能。此外,MRT在token效率上比结果奖励RL提高了1.2-1.6倍,显著减少了模型所需的token数量。在回溯搜索设置中,MRT通过减少1.6倍的token来提升线性化效率,进一步验证了其在优化测试时计算资源方面的有效性。
总体而言,MRT范式通过元强化学习的方法,显著提升了LLM在推理任务中的效率和准确性,为未来大语言模型的优化提供了新的方向。
原文和模型
【原文链接】 阅读原文 [ 2833字 | 12分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-v3
【摘要评分】 ★★★★★


相关文章



