文章摘要
【关 键 词】 视觉模型、模型开源、模型性能、昆仑芯片、训练方法
百度全新视觉理解模型Qianfan – VL直接开源,该模型具有多方面优势与特点。
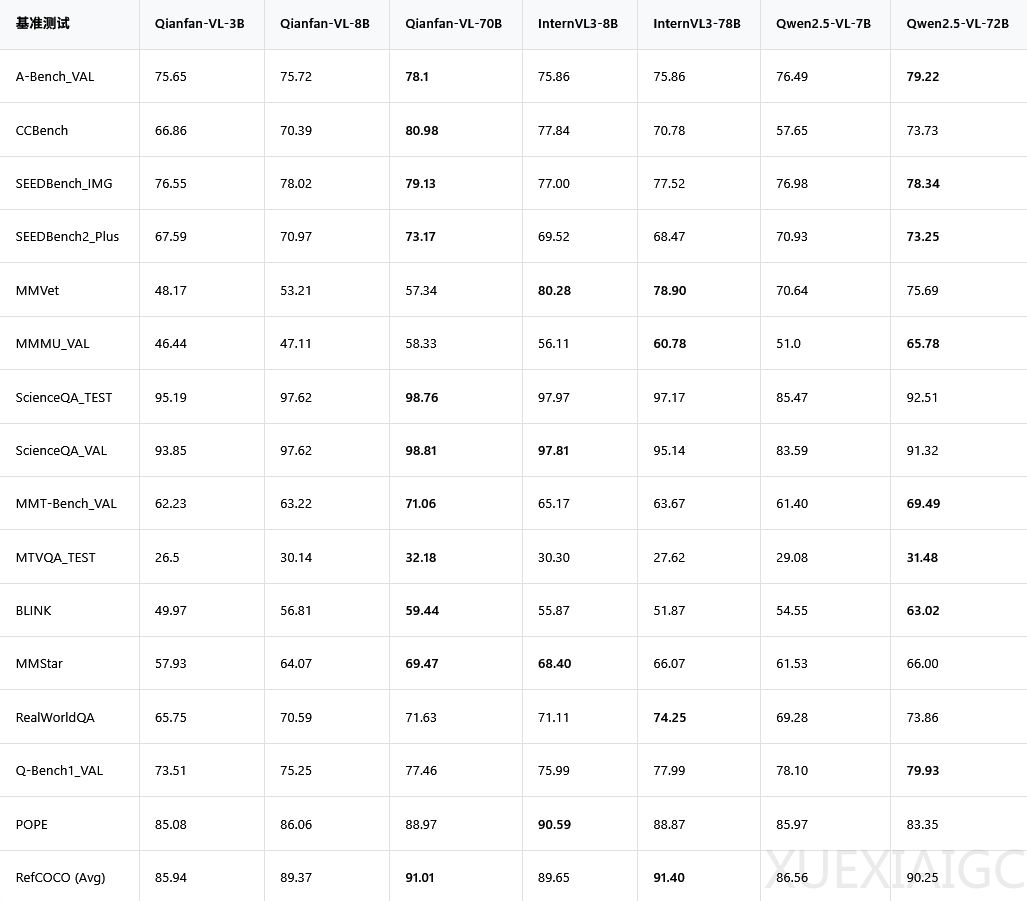
模型性能与应用表现出色:Qianfan – VL系列有3B、8B和70B三个版本,参数量不同对应不同应用场景。它是多模态大模型,具备OCR和教育场景深度优化两大核心能力。OCR实现全场景覆盖,能识别多种字体及复杂公式,还可抽取发票等单据信息;在K12教育场景,拍照解题等是其强项。跑分测试中,70B版本在ScienceQA接近满分,在CCBench中优势明显,在数学解题测试中碾压对手。
依托纯血国产芯片训练:支撑Qianfan – VL训练的是百度自研的昆仑芯P800芯片。2025年4月百度点亮国内首个全自研3万卡昆仑芯P800集群,模型训练在超5000张该芯片卡的集群完成。昆仑芯P800功耗低,其XPU – R架构采用“通算融合”技术,将计算和通信单元分开,提高芯片利用率。百度还推出“昆仑芯超节点”方案,提升带宽和单机训练性能。
独特的模型炼成方法:底层架构融合业界优秀成果,语言模型部分不同版本基于不同架构,视觉编码器用InternViT。训练采用创新的“四阶段训练管线”,包括跨模态对齐、通用知识注入、领域增强知识注入和后训练。第三阶段使用的专业数据由百度高精度数据合成管线生成。
目前,Qianfan – VL全系列模型已在GitHub、Hugging Face等平台全面开源,百度智能云的千帆平台也提供在线体验和部署服务。
原文和模型
【原文链接】 阅读原文 [ 1504字 | 7分钟 ]
【原文作者】 AIGC开放社区
【摘要模型】 doubao-1-5-pro-32k-250115
【摘要评分】 ★★☆☆☆

© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章

暂无评论...



