出人意料!DeepSeek-R1用的GRPO其实非最优?规模化强化学习训练用PPO就够了
文章摘要
【关 键 词】 强化学习、GRPO算法、PPO优化、开源模型、训练效率
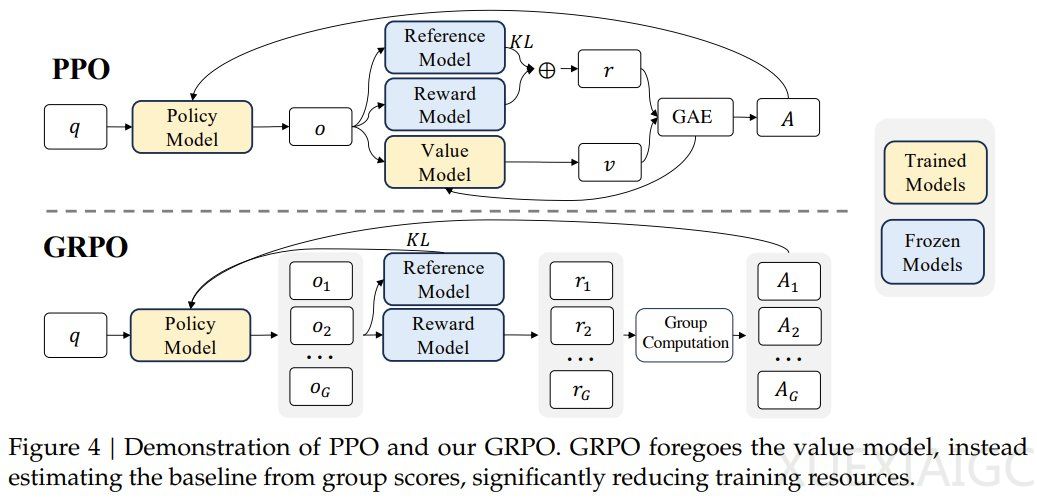
DeepSeek-R1模型的核心强化学习算法GRPO通过分组分数替代价值模型,显著降低了训练资源消耗。然而,阶跃星辰与清华大学的最新研究表明,采用带GAE(λ=1,γ=1)的标准PPO算法与基于规则的二元奖励函数,无需KL正则化即可实现与DeepSeek-R1-Zero相当的推理性能扩展。该团队基于Qwen2.5基础模型开发的开源框架Open-Reasoner-Zero,在GPQA Diamond基准上以1/30的训练步数超越DeepSeek-R1-Zero-Qwen-32B,同时公开了完整的代码、参数配置及模型权重。
研究团队构建了包含57,000个样本的多样化数据集,覆盖STEM、数学与推理任务,通过特定提示模板引导模型生成结构化响应。其设计的奖励函数仅验证答案正确性,不涉及格式约束,结果显示基础模型能快速适应目标格式。实验采用改进的PPO算法,设置GAE参数λ=1.0、折扣因子γ=1.0和clipping参数ε=0.2,在7B和32B模型规模上均实现了稳定训练。训练曲线显示,模型在奖励值、响应长度等指标上持续提升,并出现“阶跃时刻”现象——特定训练阶段后,反思模式响应显著增加,推理能力呈现涌现特性。
关键发现表明,简化奖励函数设计可有效避免奖励黑客风险,而扩大数据规模与多样性是性能持续提升的核心因素。与传统认知不同,KL正则化并非必要,且GAE参数在推理任务中需特殊配置。Open-Reasoner-Zero-32B模型仅用DeepSeek-R1-Zero 17.2%的训练步数即达到相近的响应长度扩展效果,验证了该方法的效率优势。在MMLU_PRO和IFEval基准测试中,模型未经过指令微调即展现出优于Qwen2.5 Instruct 32B的泛化能力,证明纯强化学习训练对知识密集型任务的适用性。
研究还揭示了模型生成行为的量化特征:包含反思模式的响应平均长度超出普通响应15%,且正确率更高,表明扩展响应空间有助于提升推理质量。这些发现为大规模强化学习在复杂推理任务中的应用提供了新范式,其开源生态或将加速相关领域的技术迭代。
原文和模型
【原文链接】 阅读原文 [ 2937字 | 12分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek-r1
【摘要评分】 ★★★★☆


相关文章




