从RLHF、PPO到GRPO再训练推理模型,这是你需要的强化学习入门指南
文章摘要
【关 键 词】 强化学习、GRPO、模型训练、奖励函数、智能体
强化学习已成为大型语言模型(LLM)技术栈的核心组成部分,其应用范围从模型对齐、推理训练扩展到新兴的智能体强化学习(Agentic RL)。Unsloth团队近期发布的强化学习教程系统性地介绍了从基础概念到前沿技术(如GRPO)的完整知识体系,并通过吃豆人等直观案例阐释了强化学习的核心机制。
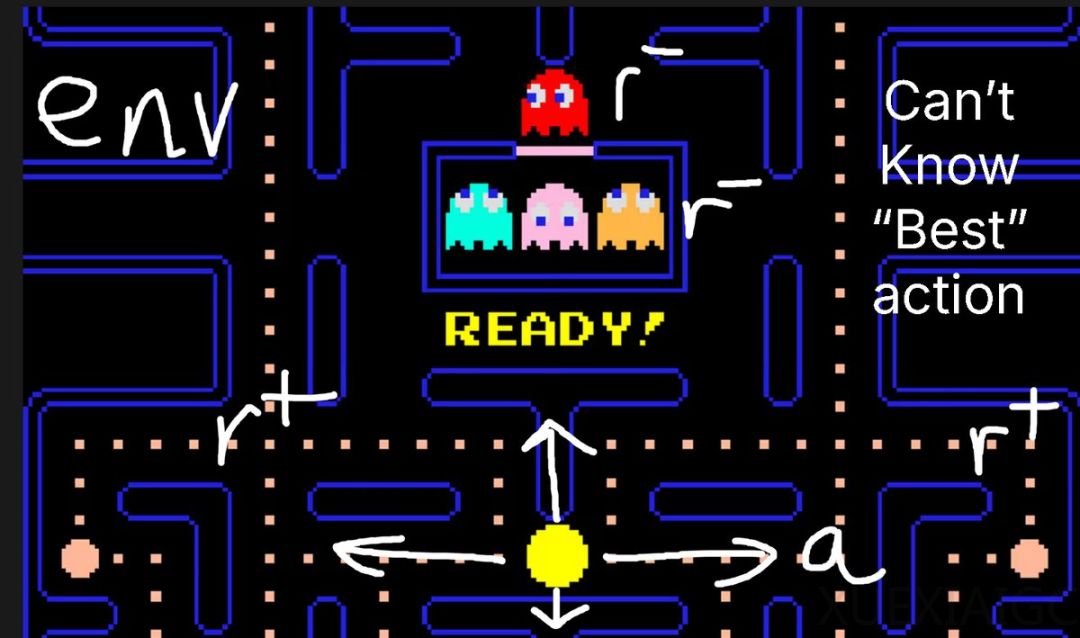
强化学习的本质是通过奖励信号引导模型优化行为分布。在典型场景中,环境(如游戏世界)、动作空间(如移动方向)和奖励函数(如得分机制)构成基础框架。以数学问答为例,模型输出”4″获得正奖励,输出无关字符则触发负反馈,这种机制通过反复迭代逐步修正模型的概率分布。值得注意的是,强化学习不依赖预先标注的最优动作,而是通过试错过程中的即时反馈实现自我改进。
技术演进方面,教程详细对比了不同范式的创新突破。RLHF(基于人类反馈的强化学习)通过人类偏好数据训练奖励模型,PPO(近端策略优化)则引入参考策略和价值模型来稳定训练过程。而DeepSeek提出的GRPO(组相对策略优化)通过两项关键改进显著提升效率:移除独立的价值模型,改为采样统计估算优势函数;采用可验证奖励机制(RLVR),特别适用于数学推导、代码生成等可客观评估的任务。这种设计使得GPU内存占用降低4倍,同时保持训练稳定性。
在实践层面,教程揭示了强化学习成功的关键要素是设计有效的奖励函数和验证机制。验证器负责判断输出的正确性(如代码能否执行),而奖励函数则将其量化为数值信号。优秀的奖励设计需要兼顾多维度标准,例如在邮件自动化任务中,同时评估关键词匹配度、内容长度和格式规范。值得注意的是,基于邻近度的动态奖励函数能更精细地引导模型——对接近正确答案的输出给予梯度式奖励,这比简单的二元评判更具指导性。
Unsloth框架为GRPO实施提供了完整工具链,支持在消费级GPU(最低5GB显存)上微调17B参数以下的模型。其优化建议包括:训练至少持续300步才能观察到显著改进,500条以上的数据量能保证效果,而1.5B参数是模型具备推理能力的最低门槛。教程特别强调,强化学习本质是概率游戏——只要正确答案存在于模型的潜在输出空间中,通过持续的奖励引导和坏答案抑制,最终能实现理想的输出分布。
该资源还包含多个实战案例,如使用GSM8K数据集训练数学推理模型,以及自定义XML标签的格式校验函数。这些示例展示了GRPO在超越简单问答的复杂场景中的应用潜力,包括法律文书生成、医疗诊断辅助等专业领域。团队开源的Colab笔记本更详细演示了从基础模型加载、奖励函数设计到训练监控的全流程,为开发者提供了即用型解决方案。
原文和模型
【原文链接】 阅读原文 [ 4048字 | 17分钟 ]
【原文作者】 机器之心
【摘要模型】 deepseek/deepseek-v3-0324
【摘要评分】 ★★★★★


相关文章




